For some possibly narcissistic reason, I have always wanted to know at least something about who reads my blog(s) or access my websites. Maybe it is some leftover habit from Social Media where the popularity of a post is sold as a proxy to measure the quality of a post, maybe it is just the fact that I am curious, or maybe I just wanted another toy to play with. Either way, I woke up this weekend with the intention to build some analytics into this blog, and this post is about how I implemented that.
Constraints
Let’s start with a few self-imposed constraints, which hopefully will clarify whether this is a similar or a completely different use-case compared to yours:
- No Javascript. I could probably end the list here, since basically all analytics platforms use JS. However, this site is without JS and I want it to keep it like this.
- No tracking. I don’t want to collect any personal data whatsoever, including for example IP addresses. I don’t care about that, because mostly I don’t care about such in-depth data.
- Lightweight. Whatever I will use, needs to consume as little resources as possible.
Requirements
After mentioning the constraints, let’s talk about the requirements. I wanted to achieve the following:
- Being able to understand which pages of the blogs are visited.
- Having a rough estimate of how much traffic is from bots, how much is from RSS readers, how much is just from regular browsers.
As you can see, the requirements are very minimal. This is also because I am aware that with the imposed constraints, you can’t do much more than that as there is no data.
Design
Since Javascript was out of question, the only other way to build some sort of analytics (I know) relies on logs. Specifically, in my case, reverse proxy logs.
I use traefik as reverse proxy, so the plan was fairly straightforward:
- Configure logging with Traefik to include relevant fields (and discard irrelevant).
- Spin up a log aggregator that has the capability to build dashboards.
- Forward parsed Traefik logs to the aggregator.
- Create dashboards.
The only tiny problem is that until yesterday I did not have a log aggregator, nor any log-forwarder/parsers on the server.
Log Aggregator Choice
The first step was therefore to choose the tool to use for log aggregation. Professionally I have hosted Elasticsearch clusters, but I really wanted to stay away from that because of the operational overhead, resource consumption and generally because it is way overkill for my use-case.
There are forks/derivatives of ES as well, such as Graylog, Opensearch, etc., which are also an option, but that I decided to avoid for the same reason.
The main two candidates for my specific use-case were:
The first, is a real-time log parser with quite some capabilities, including
dashboards (HTML-generated). It is written in C and it is fairly minimal.
To be honest, I am quite fond of this tool and I am thinking that in the future
I might actually include it in some analytics page in this very website.
My choice though fell on openobserve. This is a relatively new tool, written
in Rust, which aims to be an all-in-one observability tool. Generally, I am not
very fond of “all-in-one” stuff, and at the moment, I don’t really care about
tracing, while I already have a Prometheus/Grafana stack for metrics. However,
I do (did) lack the capability to centralize logs, and while web-analytics
for this blog was the main reason that pushed me to do this work, I think I will
be use this chance to also centralize other logs, such as the logs from my
domestic Kubernetes cluster and from other applications I run.
Log Forwarder Choice
Once the log aggregator problem was solved, it remained the question mark on how to deliver logs to it. There are a bunch of tools that can do log forwarding, and to be honest, in this case I don’t think there is substantial difference between them (at least, for this use-case). The few alternatives I have considered:
Fluentd(written in Ruby, I used it professionally).Fluentbit(written in C, much faster thanfluentd).Filebeat(written in Go, part of elastic Ecosystem).Vector(written in Rust, made by Datadog?).
I decided to try the only tool I didn’t use before, which is vector. Once again,
for this use-case, I didn’t have any stringent criteria, I just needed to tail
one file, parse logs and send them to openobserve, any tool would likely have
fit.
Setup
Traefik
First, I configured Traefik logging, as follows:
accessLog:
filePath: "/data/traefik.log"
format: json
fields:
defaultMode: drop
names:
DownstreamStatus: keep
RequestHost: keep
RequestCount: keep
RequestMethod: keep
RequestPath: keep
RequestScheme: keep
RouterName: keep
ServiceName: keep
entryPointName: keep
headers:
defaultMode: drop
names:
User-Agent: keep
Vector
To run the forwarder, I decided to apply what I have discussed in
my previous blog post. Vector offers
distroless-based containers, and I decided to go in this direction
compared to a hardened Systemd unit. Note that log-forwarding is one
of those uses-cases where a Systemd unit might be a good choice,
especially if there are many log sources. In my case there is only
one (at the moment), so this was not a problem.
To run vector, I have used a simple docker-compose file:
version: '3'
services:
vector:
# Use the distrolles tag
image: timberio/vector:0.34.1-distroless-static
volumes:
# Mount the vector config from the host
- /volume0/vector/data/vector.toml:/etc/vector/vector.toml:ro
# Needed to statically configure DNS name for my internal host
- /volume0/vector/data/hosts:/etc/hosts:ro
# Some persistent path for vector to store checkpoints
- /volume0/vector/data/indices:/indices
# The path where the traefik logs are saved
- /volume0/traefik/logs:/data/traefik:ro
# Mount the CAs from the host since they include my internal CA
- /etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt:ro
# Configure vector to read my config, not the default vector.yaml
# not sure why they included a sample config in the image...
command: --config=/etc/vector/vector.toml
After this, I just have to provide the configuration file:
data_dir="/indices"
[sources.traefik_logs]
type= "file"
include= ["/data/traefik/traefik.log"]
[transforms.parse]
type = "remap"
inputs = ["traefik_logs"]
source = '''
.message = parse_json!(string!(.message), max_depth: 1)
.status = .message.DownstreamStatus
.host = .message.RequestHost
.method = .message.RequestMethod
.path = .message.RequestPath
.service = .message.ServiceName
.entrypoint = .message.EntrypointName
.level = .message.level
.user_agent = .message."request_User-Agent"
.timestamp = .message.timestamp
del(.message)
'''
[sinks.openobserve]
type = "http"
inputs = [ "parse" ]
uri = "https://[OPENOBSERVE_URL]/api/default/traefik/_json"
method = "post"
batch.max_events=100
batch.max_bytes=100000
auth.strategy = "basic"
auth.user = "[OPENOBSERVE_USER - REDACTED]"
auth.password = "[OPENOBSERVE_PASS - REDACTED]"
compression = "gzip"
encoding.codec = "json"
encoding.timestamp_format = "rfc3339"
healthcheck.enabled = false
Note that in the configuration above I configure the following:
- A
source, to read the log file - Then a
transformwhich essentially parses the JSON log and creates new fields based on the parsed JSON. - Finally a
sinkthat delivers the logs to my openobserve, specifically in a stream I calledtraefik.
This can essentially be seen as a pipeline:
Read (source) -> parse (transform) -> send (sink)
Just to touch on the security aspect:
- This container has only access to the Traefik logs path, and that path is mounted as Read-Only, so that they cannot be tampered (not that it would matter much in my case).
- The image is minimal, but runs as
root. I will try to open a PR upstream to instead add theDAC_READ_SEARCHcapability (and maybe theNET_BIND_SERVICEcapability, which I think are the only ones needed. - The container runs just in the Docker network, and does not expose any port.
Openobserve Setup
I decided to run Openobserve in my domestic Kubernetes cluster, and to be honest the setup was surprisingly easy. I have deviated very slightly from the official manifests, but the gist is the same.
We need:
- An ingress (to let external tools, like Vector, push logs).
- A PV/PVC to store data
- A Statefulset to run the tool (in my case, a single-instance is fine).
- A Service to route traffic.
- A Secret to hold the initial password (rather than including it in the STS manifest!).
The result is the following in my case:
apiVersion: v1
kind: Service
metadata:
name: openobserve
namespace: openobserve
spec:
clusterIP: None
ports:
- name: http
port: 5080
targetPort: 5080
selector:
app: openobserve
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
labels:
app: openobserve
name: openobserve-data
namespace: openobserve
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
# I am using OpenEBS
storageClassName: openebs-hostpath
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
name: openobserve
name: openobserve
namespace: openobserve
spec:
replicas: 1
selector:
matchLabels:
app: openobserve
name: openobserve
serviceName: openobserve
template:
metadata:
labels:
app: openobserve
name: openobserve
spec:
containers:
- env:
- name: ZO_ROOT_USER_EMAIL
value: [OPENOBSERVE_USER - REDACTED]
- name: ZO_ROOT_USER_PASSWORD
valueFrom:
secretKeyRef:
key: pass
name: openobserve-pass
- name: ZO_DATA_DIR
value: /data
image: [CONTAINER_REGISTRY]/openobserve@sha256:b60d4a0fc104ab18be58470796053097631041fa1952027e4f95e80f574e3f0e
imagePullPolicy: Always
name: openobserve
ports:
- containerPort: 5080
name: http
resources:
limits:
# Do not include CPU limits and set memory req = memory limit
# https://home.robusta.dev/blog/stop-using-cpu-limits
memory: 500Mi
requests:
cpu: 256m
memory: 500Mi
volumeMounts:
- mountPath: /data
name: openobserve-data
# Needed to pull the image from my private registry - Gitea
imagePullSecrets:
- name: gitea
securityContext:
# Do not run as root
fsGroup: 2000
runAsGroup: 3000
runAsNonRoot: true
runAsUser: 10000
volumeClaimTemplates:
- metadata:
name: openobserve-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 25Gi
storageClassName: openebs-hostpath
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: openobserve
namespace: openobserve
spec:
ingressClassName: nginx
rules:
# This is the host I added in /etc/hosts in Vector container
- host: logs.[LOCAL_DOMAIN]
http:
paths:
- backend:
service:
name: openobserve
port:
number: 5080
path: /
pathType: Prefix
I added all these manifests in a Kustomization, I created the NS and the secret manually
and then I let flux do the rest.
The End Result
The resource consumption from both Vector and Openobserve has been surprisingly low, but I also have an extremely low amount of visitors :)
Either way, I have spent very little time configuring a dashboard in Openobserve, and now this is the result:
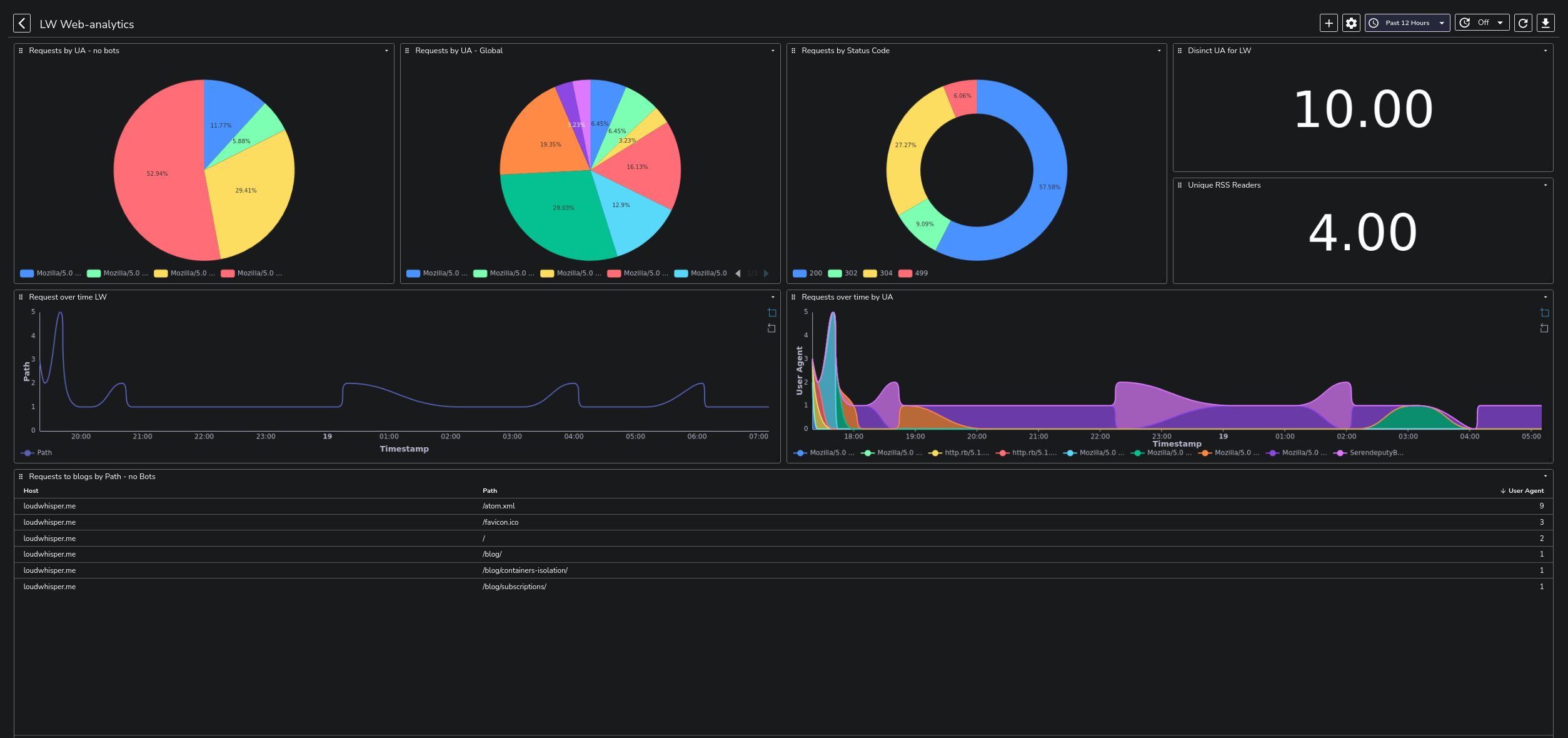
If you find an error, want to propose a correction, or you simply have any kind of comment and observation, feel free to reach out via email or via Mastodon.